

【導(dǎo)讀】學(xué)術(shù)上有個概念是“傳聲器陣列”,主要由一定數(shù)目的聲學(xué)傳感器組成,用來對聲場的空間特性進行采樣并處理的系統(tǒng)。而這篇文章講到的麥克風(fēng)陣列是其中一個狹義概念,特指應(yīng)用于語音處理的按一定規(guī)則排列的多個麥克風(fēng)系統(tǒng),也可以簡單理解為2個以上麥克風(fēng)組成的錄音系統(tǒng)。
亞馬遜Echo和谷歌Home爭奇斗艷,除了云端服務(wù),他們在硬件上到底有哪些差異?我們先將Echo和Home兩款音箱拆開來看,區(qū)別最大的還是麥克風(fēng)陣列技術(shù)。Amazon Echo采用的是環(huán)形6+1麥克風(fēng)陣列,而Google Home(包括Surface Studio)只采用了2麥克風(fēng)陣列。這種差異我們在文章《對比Amazon Echo,Google Home為何只采用了2個麥克風(fēng)?》做了探討。但是好多朋友私信咨詢,因此這里想稍微深入談?wù)匊溈孙L(fēng)陣列技術(shù),以及智能語音交互設(shè)備到底應(yīng)該選用怎樣的方案。
什么是麥克風(fēng)陣列技術(shù)?
學(xué)術(shù)上有個概念是“傳聲器陣列”,主要由一定數(shù)目的聲學(xué)傳感器組成,用來對聲場的空間特性進行采樣并處理的系統(tǒng)。而這篇文章講到的麥克風(fēng)陣列是其中一個狹義概念,特指應(yīng)用于語音處理的按一定規(guī)則排列的多個麥克風(fēng)系統(tǒng),也可以簡單理解為2個以上麥克風(fēng)組成的錄音系統(tǒng)。
麥克風(fēng)陣列一般來說有線形、環(huán)形和球形之分,嚴(yán)謹(jǐn)?shù)膽?yīng)該說成一字、十字、平面、螺旋、球形及無規(guī)則陣列等。至于麥克風(fēng)陣列的陣元數(shù)量,也就是麥克風(fēng)數(shù)量,可以從2個到上千個不等。這樣說來,麥克風(fēng)陣列真的好復(fù)雜,別擔(dān)心,復(fù)雜的麥克風(fēng)陣列主要應(yīng)用于工業(yè)和國防領(lǐng)域,消費領(lǐng)域考慮到成本會簡化很多。

為什么需要麥克風(fēng)陣列?
消費級麥克風(fēng)陣列的興起得益于語音交互的市場火熱,主要解決遠(yuǎn)距離語音識別的問題,以保證真實場景下的語音識別率。這涉及了語音交互用戶場景的變化,當(dāng)用戶從手機切換到類似Echo智能音箱或者機器人的時候,實際上麥克風(fēng)面臨的環(huán)境就完全變了,這就如同兩個人竊竊私語和大聲嘶喊的區(qū)別。
前幾年,語音交互應(yīng)用最為普遍的就是以Siri為代表的智能手機,這個場景一般都是采用單麥克風(fēng)系統(tǒng)。單麥克風(fēng)系統(tǒng)可以在低噪聲、無混響、距離聲源很近的情況下獲得符合語音識別需求的聲音信號。但是,若聲源距離麥克風(fēng)距離較遠(yuǎn),并且真實環(huán)境存在大量的噪聲、多徑反射和混響,導(dǎo)致拾取信號的質(zhì)量下降,這會嚴(yán)重影響語音識別率。而且,單麥克風(fēng)接收的信號,是由多個聲源和環(huán)境噪聲疊加的,很難實現(xiàn)各個聲源的分離。這樣就無法實現(xiàn)聲源定位和分離,這很重要,因為還有一類聲音的疊加并非噪聲,但是在語音識別中也要抑制,就是人聲的干擾,語音識別顯然不能同時識別兩個以上的聲音。
顯然,當(dāng)語音交互的場景過渡到以Echo、機器人或者汽車為主要場景的時候,單麥克風(fēng)的局限就凸顯出來。為了解決單麥克風(fēng)的這些局限性,利用麥克風(fēng)陣列進行語音處理的方法應(yīng)時而生。麥克風(fēng)陣列由一組按一定幾何結(jié)構(gòu)(常用線形、環(huán)形)擺放的麥克風(fēng)組成,對采集的不同空間方向的聲音信號進行空時處理,實現(xiàn)噪聲抑制、混響去除、人聲干擾抑制、聲源測向、聲源跟蹤、陣列增益等功能,進而提高語音信號處理質(zhì)量,以提高真實環(huán)境下的語音識別率。
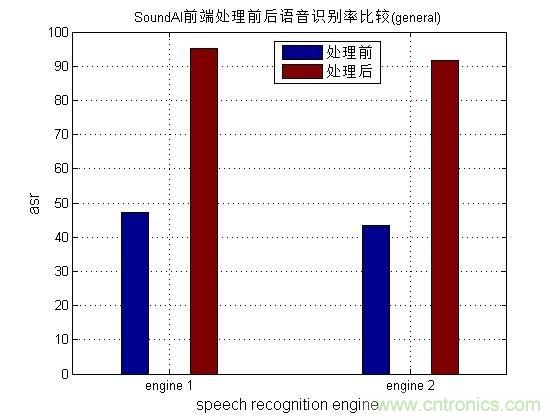
事實上,僅靠麥克風(fēng)陣列也很難保證語音識別率的指標(biāo)。麥克風(fēng)陣列還僅是物理入口,只是完成了物理世界的聲音信號處理,得到了語音識別想要的聲音,但是語音識別率卻是在云端測試得到的結(jié)果,因此這兩個系統(tǒng)必須匹配在一起才能得到最好的效果。不僅如此,麥克風(fēng)陣列處理信號的質(zhì)量還無法定義標(biāo)準(zhǔn)。因為當(dāng)前的語音識別基本都是深度學(xué)習(xí)訓(xùn)練的結(jié)果,而深度學(xué)習(xí)有個局限就是嚴(yán)重依賴于輸入訓(xùn)練的樣本庫,若處理后的聲音與樣本庫不匹配則識別效果也不會太好。從這個角度應(yīng)該非常容易理解,物理世界的信號處理也并非越是純凈越好,而是越接近于訓(xùn)練樣本庫的特征越好,即便這個樣本庫的訓(xùn)練信號很差。顯然,這是一個非常難于實現(xiàn)的過程,至少要聲學(xué)處理和深度學(xué)習(xí)的兩個團隊配合才能做好這個事情,另外聲學(xué)信號處理這個層次輸出的信號特征對語義理解也非常重要??磥恚⌒〉柠溈孙L(fēng)陣列還真的不是那么簡單,為了更好地顯示這種差別,我們測試了某語音識別引擎在單麥克風(fēng)和四麥克風(fēng)環(huán)形陣列的識別率對比。另外也要提醒,語音識別率并非只有一個WER指標(biāo),還有個重要的虛警率指標(biāo),稍微有點聲音就亂識別也不行,另外還要考慮閾值的影響,這都是麥克風(fēng)陣列技術(shù)中的陷阱。
麥克風(fēng)陣列的關(guān)鍵技術(shù)
消費級的麥克風(fēng)陣列主要面臨環(huán)境噪聲、房間混響、人聲疊加、模型噪聲、陣列結(jié)構(gòu)等問題,若使用到語音識別場景,還要考慮針對語音識別的優(yōu)化和匹配等問題。為了解決上述問題,特別是在消費領(lǐng)域的垂直場景應(yīng)用環(huán)境中,關(guān)鍵技術(shù)就顯得尤為重要。
噪聲抑制:語音識別倒不需要完全去除噪聲,相對來說通話系統(tǒng)中需要的技術(shù)則是噪聲去除。這里說的噪聲一般指環(huán)境噪聲,比如空調(diào)噪聲,這類噪聲通常不具有空間指向性,能量也不是特別大,不會掩蓋正常的語音,只是影響了語音的清晰度和可懂度。這種方法不適合強噪聲環(huán)境下的處理,但是應(yīng)付日常場景的語音交互足夠了。
混響消除:混響在語音識別中是個蠻討厭的因素,混響去除的效果很大程度影響了語音識別的效果。我們知道,當(dāng)聲源停止發(fā)聲后,聲波在房間內(nèi)要經(jīng)過多次反射和吸收,似乎若干個聲波混合持續(xù)一段時間,這種現(xiàn)象叫做混響?;祉憰?yán)重影響語音信號處理,比如互相關(guān)函數(shù)或者波束主瓣,降低測向精度。

回聲抵消:嚴(yán)格來說,這里不應(yīng)該叫回聲,應(yīng)該叫“自噪聲”?;芈暿腔祉懙难由旄拍?,這兩者的區(qū)別就是回聲的時延更長。一般來說,超過100毫秒時延的混響,人類能夠明顯區(qū)分出,似乎一個聲音同時出現(xiàn)了兩次,我們就叫做回聲,比如天壇著名的回聲壁。實際上,這里所指的是語音交互設(shè)備自己發(fā)出的聲音,比如Echo音箱,當(dāng)播放歌曲的時候若叫Alexa,這時候麥克風(fēng)陣列實際上采集了正在播放的音樂和用戶所叫的Alexa聲音,顯然語音識別無法識別這兩類聲音。回聲抵消就是要去掉其中的音樂信息而只保留用戶的人聲,之所以叫回聲抵消,只是延續(xù)大家的習(xí)慣而已,其實是不恰當(dāng)?shù)摹?/div>
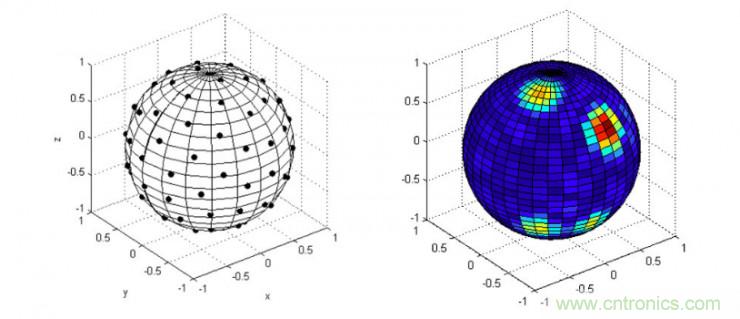
聲源測向:這里沒有用聲源定位,測向和定位是不太一樣的,而消費級麥克風(fēng)陣列做到測向就可以了,沒必要在這方面投入太多成本。聲源測向的主要作用就是偵測到與之對話人類的聲音以便后續(xù)的波束形成。聲源測向可以基于能量方法,也可以基于譜估計,陣列也常用TDOA技術(shù)。聲源測向一般在語音喚醒階段實現(xiàn),VAD技術(shù)其實就可以包含到這個范疇,也是未來功耗降低的關(guān)鍵研究內(nèi)容。
波束形成:波束形成是通用的信號處理方法,這里是指將一定幾何結(jié)構(gòu)排列的麥克風(fēng)陣列的各麥克風(fēng)輸出信號經(jīng)過處理(例如加權(quán)、時延、求和等)形成空間指向性的方法。波束形成主要是抑制主瓣以外的聲音干擾,這里也包括人聲,比如幾個人圍繞Echo談話的時候,Echo只會識別其中一個人的聲音。
陣列增益:這個比較容易理解,主要是解決拾音距離的問題,若信號較小,語音識別同樣不能保證,通過陣列處理可以適當(dāng)加大語音信號的能量。
模型匹配:這個主要是和語音識別以及語義理解進行匹配,語音交互是一個完整的信號鏈,從麥克風(fēng)陣列開始的語音流不可能割裂的存在,必然需要模型匹配在一起。實際上,效果較好的語音交互專用麥克風(fēng)陣列,通常是兩套算法,一套內(nèi)嵌于硬件實時處理,另外一套服務(wù)于云端匹配語音處理。
麥克風(fēng)陣列的技術(shù)趨勢
語音信號其實是不好處理的,我們知道信號處理大多基于平穩(wěn)信號的假設(shè),但是語音信號的特征參數(shù)均是隨時間而變化的,是典型的非平穩(wěn)態(tài)過程。幸運的是語音信號在一個較短時間內(nèi)的特性相對穩(wěn)定(語音分幀),因而可以將其看作是一個準(zhǔn)穩(wěn)態(tài)過程,也就是說語音信號具有短時平穩(wěn)的特性,這才能用主流信號處理方法對其處理。從這點來看,麥克風(fēng)陣列的基本原理和模型方面就存在較大的局限,也包括聲學(xué)的非線性處理(現(xiàn)在基本忽略非線性效應(yīng)),因此基礎(chǔ)研究的突破才是未來的根本。希望能有更多熱愛人工智能的學(xué)生關(guān)注聲學(xué),報考我們中科院聲學(xué)所。
另外一個趨勢就是麥克風(fēng)陣列的小型化,麥克風(fēng)陣列受制于半波長理論的限制,現(xiàn)在的口徑還是較大,聲智科技現(xiàn)在可以做到2cm-8cm的間距,但是結(jié)構(gòu)布局仍然還是限制了ID設(shè)計的自由性。很多產(chǎn)品采用2個麥克風(fēng)其實并非成本問題,而是ID設(shè)計的考慮。實際上,借鑒雷達(dá)領(lǐng)域的合成孔徑方法,麥克風(fēng)陣列可以做的更小,而且這種方法已經(jīng)在軍工領(lǐng)域成熟驗證,移植到消費領(lǐng)域只是時間問題。
還有一個趨勢是麥克風(fēng)陣列的低成本化,當(dāng)前無論是2個麥克風(fēng)還是4、6個麥克風(fēng)陣列,成本都是比較高的,這影響了麥克風(fēng)陣列的普及。低成本化不是簡單的更換芯片器件,而是整個結(jié)構(gòu)的重新設(shè)計,包括器件、芯片、算法和云端。這里要強調(diào)一下,并非2個麥克風(fēng)的陣列成本就便宜,實際上2個和4個麥克風(fēng)陣列的相差不大,2個麥克風(fēng)陣列的成本也要在60元左右,但是這還不包含進行回聲抵消的硬件成本,若綜合比較,實際上成本相差不大。特別是今年由于新技術(shù)的應(yīng)用,多麥克風(fēng)陣列的成本下降非常明顯。
再多說一個趨勢就是多人聲的處理和識別,其中典型的是雞尾酒會效應(yīng),人的耳朵可以在嘈雜的環(huán)境中分辨想要的聲音,并且能夠同時識別多人說話的聲音?,F(xiàn)在的麥克風(fēng)陣列和語音識別還都是單人識別模式,距離多人識別的目標(biāo)還很遠(yuǎn)。前面提到了現(xiàn)在的算法思想主要是“抑制”,而不是“利用”,這實際上就是人為故意簡化了物理模型,說白了就是先拿“軟柿子”下手,因此語音交互格局已定的說法經(jīng)不起推敲,對語音交互的認(rèn)識和探究應(yīng)該說才剛剛開始,基礎(chǔ)世界的探究很可能還會出現(xiàn)諾獎級的成果。若展望的更遠(yuǎn)一些,則是物理學(xué)的進展和人工智能的進展相結(jié)合,可能會顛覆當(dāng)前的聲學(xué)信號處理以及語音識別方法。
如何選用麥克風(fēng)陣列?
當(dāng)前成熟的麥克風(fēng)陣列的主要包括:訊飛的2麥、4麥和6麥方案,思必馳的6+1麥方案,云知聲(科勝訊)的2麥方案,以及聲智科技的單麥、2麥陣列、4(+1)麥陣列、6(+1)麥陣列和8(+1)麥陣列方案,其他家也有麥克風(fēng)陣列的硬件方案,但是缺乏前端算法和云端識別的優(yōu)化。由于各家算法原理的不同,有些陣列方案可以由用戶自主選用中間的麥克風(fēng),這樣更利于用戶進行ID設(shè)計。其中,2個以上的麥克風(fēng)陣列又分為線形和環(huán)形兩種主流結(jié)構(gòu),而2麥的陣列則又有Broadside和Endfire兩種結(jié)構(gòu),限于篇幅我們以后的文章再展開敘述。
如此眾多的組合,那么廠商該如何選擇這些方案呢?首先還是要看產(chǎn)品定位和用戶場景。若定位于追求性價比的產(chǎn)品,其實就不用考慮麥克風(fēng)陣列方案,就直接采用單麥方案,利用算法進行優(yōu)化,也可實現(xiàn)噪聲抑制和回聲抵消,能夠保證近場環(huán)境下的語音識別率,而且成本絕對要低很多。至于單麥語音識別的效果,可以體驗下采用聲智科技單麥識別算法的360兒童機器人。
但是若想更好地去除部分噪聲,可以選用2麥方案,但是這種方案比較折衷,主要優(yōu)點就是ID設(shè)計簡單,在通話模式(也就是給人聽)情況下可以去除某個范圍內(nèi)的噪音。但是語音識別(也就是給機器聽)的效果和單麥的效果卻沒有實質(zhì)區(qū)別,成本相對也比較高,若再考慮語音交互終端必要的回聲抵消功能,成本還要上升不少。2麥方案最大的弊端還是聲源定位的能力太差,因此大多是用在手機和耳機等設(shè)備上實現(xiàn)通話降噪的效果。這種降噪效果可以采用一個指向性麥克風(fēng)(比如會議話筒)來模擬,這實際上就是2麥的Endfire結(jié)構(gòu),也就是1個麥克風(fēng)通過原理設(shè)計模擬了2個麥克風(fēng)的功能。指向性麥克風(fēng)的不方便之處就是ID設(shè)計需要前后兩個開孔,這很麻煩,例如叮咚1代音箱采用的就是這種指向性麥克風(fēng)方案,因此采用了周邊一圈的懸空設(shè)計。
若希望產(chǎn)品能適應(yīng)更多用戶場景,則可以類似亞馬遜Echo一樣直接選用4麥以上的麥克風(fēng)陣列。這里簡單給個參考,機器人一般4個麥克風(fēng)就夠了,音箱建議還是選用6個以上麥克風(fēng),至于汽車領(lǐng)域,最好是選用其他結(jié)構(gòu)形式的麥克風(fēng)陣列,比如分布式陣列。
多個麥克風(fēng)陣列之間的成本差異現(xiàn)在正在變小,估計明年的成本就會相差不大。這是趨勢,新興的市場剛開始成本必然偏高,但隨著技術(shù)進步和規(guī)模擴張,成本會快速走低,因此新興產(chǎn)品在研發(fā)階段倒是不需要太過糾結(jié)成本問題,用戶體驗才是核心的關(guān)鍵。
本文作者陳孝良,工學(xué)博士,聲智科技創(chuàng)始人。
推薦閱讀:
推薦閱讀:


