
【導讀】過去二十年來,基于 DRAM 的計算機內存的存取帶寬已經提升了 20 倍,容量增長了 128 倍。但延遲表現(xiàn)僅有 1.3 倍的提升,卡內基梅隆大學的研究者 Kevin Chang 如是說,他提出了一種用于解決該問題的新型數(shù)據通路…
如果人類創(chuàng)造了一個真正有自我意識的人工智能,那么等待數(shù)據到達可能會讓它倍感沮喪。
過去二十年來,基于 DRAM 的計算機內存的存取帶寬已經提升了 20 倍,容量增長了 128 倍。但延遲表現(xiàn)僅有 1.3 倍的提升,卡內基梅隆大學的研究者 Kevin Chang 如是說,他提出了一種用于解決該問題的新型數(shù)據通路。
現(xiàn)代計算機需要大量高速度、高容量的內存才能保證持續(xù)運轉,尤其是工作重心是內存數(shù)據庫、數(shù)據密集型分析以及越來越多的機器學習和深度神經網絡訓練功能的數(shù)據中心服務器。盡管研究人員已經在尋找更好、更快的替代技術上努力了很多年,但在性能優(yōu)先的任務上,DRAM 仍舊是人們普遍采用的選擇。
這有助于解釋今年的 DRAM 銷量激增,盡管據 IC Insights 報告稱供應有限讓其平均售價增長了 74%。售價激增讓 DRAM 市場收入達到了創(chuàng)紀錄的 720 億美元,幫助將 IC 市場的總收入推升了 22%。據這份 IC Insights 報告說,如果沒有來自 DRAM 價格的額外增長(過去 12 個月增長了 111%),那么 2017 年整個 IC 市場的增長將只能達到 9%,相比而言 2016 年僅有 4%。
對于 DRAM 這樣一個很多人都想替代的成熟技術而言(因為它的速度達不到處理器一樣快),這個數(shù)字確認驚人。當前或未來有望替代 DRAM 的技術有很多,但專家們似乎認為這些技術還無法替代 DRAM 的性價比優(yōu)勢。就算用上 DRAM 技術上規(guī)劃的改進方案以及 HBM2 和 Hybrid Memory Cube 等新型 DRAM 架構,DRAM 和 CPU 之間的速度差距依然還是存在。
Rambus 的系統(tǒng)與解決方案副總裁和杰出發(fā)明家 Steven Woo 在 CTO 辦公室中說,來自 JEDEC 的下一代 DRAM 規(guī)格 DDR5 的密度和帶寬都是 DDR4 的 2 倍,可能能夠帶來一些提速。
對于需要密集計算而且對時間敏感的金融技術應用以及其它高端分析、HPC 和超級計算應用而言,這將會非常重要——尤其是當與專用加速器結合起來時。
Woo 說:“對更高內存帶寬和更大內存容量的需求是顯然存在的,但 DDR5 本身并不足以滿足這些需求,我們也不清楚其它哪些技術可能會取得成功。我們已經看到很多處理過程(比如加密貨幣挖礦和神經網絡訓練)正從傳統(tǒng)的 x86 處理器向 GPU 和專用芯片遷移,或者對架構進行一些修改,讓數(shù)據中心中的處理更靠近數(shù)據的存儲位置,就像邊緣計算或霧計算。”
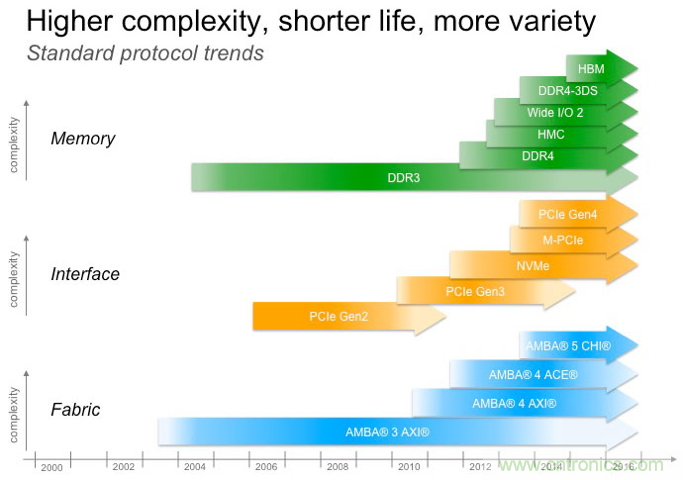
圖 1:新標準的引入(source: Cadence)
據 Babblabs 公司 CEO 兼斯坦福大學 System X 的戰(zhàn)略顧問 Chris Rowen 說,對于在神經網絡上訓練機器學習應用而言,GPU 顯然最受歡迎的,但芯片制造商和系統(tǒng)制造商也在實驗一些稍微成熟的技術,比如 GDDR5,這是一種為游戲機、顯卡和 HPC 開發(fā)的同步圖形 RAM,英偉達也正是這么使用它的。
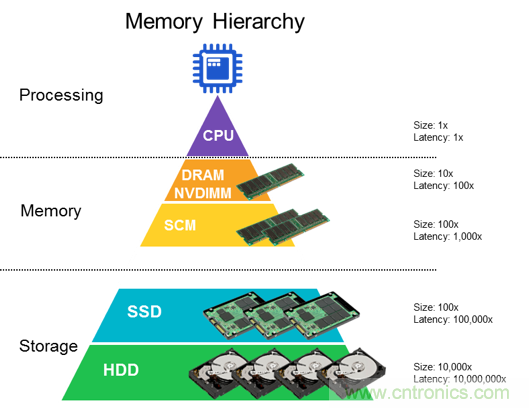
圖 2:內存在芯片層次結構中的位置(source:Rambus)
由 SK 海力士和三星制造的 HBM2 將一些高速 DRAM 芯片放在了增加了一些邏輯處理的層級以及提供了到處理器的高速數(shù)據鏈路的 interposer 之上,從而讓內存與處理器之間的距離比 GDDR5 的設計更近。HBM2 是高速度至關重要的 2.5D 封裝中的一項關鍵元素。HBM2 是一項與 Hybrid Memory Cube 相競爭的 JEDEC 標準。Hybrid Memory Cube 是由 IBM 和美光開發(fā)的,使用了過硅通孔(TSV)來將不同的內存層連接到基礎邏輯層。
應用硅光子學的光學連接(optical connection)也能實現(xiàn)加速。到目前維持,大多數(shù)硅光子學應用都在數(shù)據中心中的服務器機架和存儲之間以及高速網絡連接設備內部。業(yè)內專家預計這種技術將會在未來幾年里向離處理器更近的位置遷移,尤其是當其封裝技術得到完全驗證并且設計流程將這項技術包含進來之后。光學方法的優(yōu)勢是發(fā)熱很慢而且速度非??欤獠ㄟ€是要在轉換成電信號之后才能存儲和處理數(shù)據。
另外還有 Gen-Z、CCIX、OpenCAPI 等新型互連標準,也有 ReRAM、英特爾的相變 3D Xpoint、 3D NAND 和磁相變 MRAM 等新型內存類型。
NVDIMM 速度更慢但容量更大,增加電池或超級電容可以實現(xiàn)非易失性,從而讓它們可以使用更低的功耗緩存比普通 DRAM 更多的數(shù)據,并且還能保證它們在斷電時不會丟失交易數(shù)據。據八月份來自 Transparency Market Research 的一份報告稱,支持 NVDIMM 的芯片制造商包括美光和 Rambus,預計其銷售額將會從 2017 年的 7260 萬美元增長到 2025 年的 1.84 億美元。
選擇這么多,可能會讓人困惑,但針對機器學習或大規(guī)模內存數(shù)據庫或視頻流來調整內存性能會讓選擇更輕松一些,因為其中每種任務都有不同的瓶頸。Rowen 說:“實現(xiàn)帶寬增長有一些主流的選擇——DDR3、DDR4、DDR5,但你也可以嘗試其它選擇,從而讓內存帶寬滿足你想做的事情。”
Rowen 說,對于有意愿編寫直接控制 NAND 內存的代碼的人來說,整個問題可能還會更簡單;而如果是鼓搗協(xié)議和接口層,讓 NAND 看起來就像是硬盤并且掩蓋在上面寫入數(shù)據的難度,那就可能會更加困難。“有了低成本、容量和可用性,我認為在讓閃存存儲包含越來越多存儲層次上存在很多機會。” 冷卻 DRAM
Rambus 的內存與接口部門的首席科學家 Craig Hampel 說,每一種內存架構都有自己的優(yōu)勢,但它們都至少有一個其它每一種集成電路都有的缺點:發(fā)熱。如果你能可靠地排出熱量,你就可以將內存、處理器、圖形協(xié)處理器和內存遠遠更加緊密地堆積到一起,然后可以在節(jié)省出的空間中放入更多服務器,并且還能通過減少內存與系統(tǒng)其它組件之間的延遲來提升性能。
液體冷卻是讓絕緣礦物油流經組件的冷卻方法。據 IEEE Spectrum 2014 年的一篇文章稱,液體冷卻讓香港的比特幣挖礦公司 Asicminer 的 HPC 集群的冷卻成本降低了 97%,并且還減少了 90% 的空間需求。
自 2015 年以來,Rambus 就一直在與微軟合作開發(fā)用于量子計算的內存,這是微軟開發(fā)拓撲量子計算機工作的一部分。因為量子處理器只能在超低溫環(huán)境下運行(低于 -292℉/-180℃/93.15K),所以 Rambus 正為該項目測試的 DRAM 也需要在這樣的環(huán)境下工作。Rambus 在 4 月份時擴展了該項目,那時候 Hampel 說該公司已經確信寒冷能帶來重大的性能增益。
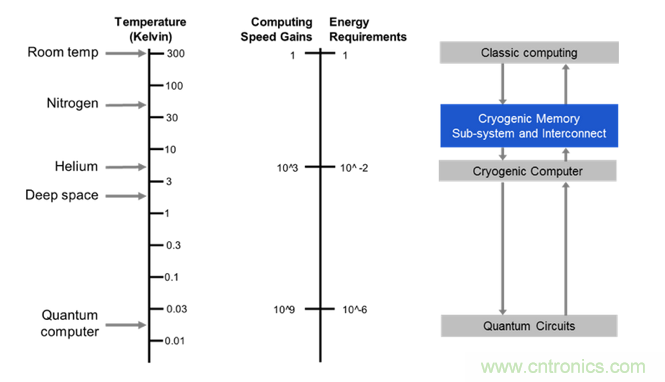
圖 3:低溫計算和存儲(source: Rambus)
比如,當 CMOS 足夠冷時,CMOS 芯片的數(shù)據泄露(data leak)就會完全停止。幾乎就會變成非易失的。它的性能會增長,能讓內存的速度趕上處理器的速度,從而消除 IC 行業(yè)內一大最頑固的瓶頸。在 4K 到 7K 這樣極端低溫的環(huán)境下,線材將變成超導體,讓芯片僅需非常少的能量就能實現(xiàn)長距離通信。
低溫系統(tǒng)還有額外的優(yōu)勢。比起空調制冷,低溫系統(tǒng)能從堆疊的內存芯片中抽取出更多熱量,從而可實現(xiàn)更大的堆疊(或其它組裝方式)密度,實現(xiàn)更高效的協(xié)作。Hampel 說:“抽取熱量讓你能將服務器機架的大小減小多達 70%,這意味著數(shù)據中心每立方英尺的密度增大了。這讓它們更容易維護,也可以更容易地將它們放在之前無法到達的地方。”
更重要的是,如果在處理器層面上實現(xiàn)的效率提升與數(shù)據中心其它地方的提升基本一致,那么低溫系統(tǒng)可以讓現(xiàn)有的數(shù)據中心更有成本效益和實現(xiàn)更高效的計算,從而可以減少對更多數(shù)據中心的需求。
而且不需要非常冷就可以收獲其中大多數(shù)效益;將內存冷卻到 77K(-321℉/-196℃)就能得到大多數(shù)效益了。
Hampel 說:“液氮很便宜——每加侖幾十美分,而且在達到大約 4 K 的超級冷之前,成本上漲其實也并不快。降到50K 左右其實并不貴。” 接近處理器
據 Marvell 存儲部門總監(jiān) Jeroen Dorgelo 說,超低溫冷卻可以延長數(shù)據中心中 DRAM 的壽命,但隨著行業(yè)從 hyperscale 規(guī)模向 zettascale 規(guī)模演進,已有的任何芯片或標準都無法應付這樣的數(shù)據流。他說,DRAM 雖快但功率需求大。NAND 不夠快,不適合擴展,而大多數(shù)前沿的內存(3D XPoint、MRAM、ReRAM)也還無法充分地擴展。
但是大多數(shù)數(shù)據中心還沒有處理好變得比現(xiàn)在遠遠更加分布式的需求。據 Marvell 的連接、存儲和基礎設施業(yè)務部網絡連接 CTO Yaniv Kopelman 說,分布式有助于減少遠距離發(fā)送給處理器的數(shù)據的量,同時可將大多數(shù)繁重的計算工作留在數(shù)據中心。
IDC 的數(shù)據中心硬件分析師 Shane Rau 說,社交網絡、物聯(lián)網和幾乎其它每個地方的數(shù)據所帶來的壓力正迫使數(shù)據中心蔓延擴展——在全國各地建立兩三個大規(guī)模數(shù)據中心,而不是在單一一個地方建一個超大規(guī)模數(shù)據中心。
Rau 說:“規(guī)模確實不一樣,但問題的關鍵仍然是延遲。比如說,如果我旁邊就有一個數(shù)據中心,我就不需要將我的數(shù)據移動太遠距離,而且我可以在我的筆記本電腦上完成一些處理,更多的處理則在本地數(shù)據中心中進行,所以在數(shù)據到達它要到達的位置時已經經過一些處理了。很多人在談將處理工作放到存儲的位置是為了平衡不同設備基礎上的瓶頸?,F(xiàn)在,規(guī)模問題更多是關于讓數(shù)據中心在邊緣完成一些工作,即數(shù)據的產生位置和數(shù)據的最終去處之間。”
推薦閱讀:


