

【導(dǎo)讀】本文針對帶有七段碼的數(shù)字液晶屏,設(shè)計了一種基于安卓手機(jī)的液晶屏數(shù)字識別系統(tǒng)。實際檢測結(jié)果表明識別率很高,而且識別速度很快,該系統(tǒng)基于安卓手機(jī),使用方便,便于攜帶,可以實時操作。
通過手機(jī)拍照獲取液晶屏圖像,利用安卓本地接口功能調(diào)用計算機(jī)視覺庫,對圖像進(jìn)行處理;針對圖像的傾斜問題,通過圖像預(yù)處理和霍夫變換取得圖像傾斜角,并進(jìn)行傾斜矯正;利用直方圖對數(shù)字字符進(jìn)行分割,以網(wǎng)格法提取字符的特征值,用三層BP神經(jīng)網(wǎng)絡(luò)進(jìn)行液晶屏數(shù)字字符的識別。實際檢測結(jié)果表明識別率很高,而且識別速度很快,該系統(tǒng)基于安卓手機(jī),使用方便,便于攜帶,可以實時操作。
隨著我國信息化建設(shè)和現(xiàn)代化進(jìn)程的加快,自動識別技術(shù)已經(jīng)越來越廣泛地應(yīng)用在各個工程領(lǐng)域,利用數(shù)字圖像識別技術(shù)可以有效地加快自動化、智能化進(jìn)程。液晶屏作為智能化設(shè)備的主要標(biāo)志,其識別已經(jīng)成為模式識別領(lǐng)域的重要研究課題。帶有七段碼的數(shù)字液晶屏,其顯示精度高,易于讀取和設(shè)置,在工業(yè)領(lǐng)域應(yīng)用非常廣泛。利用現(xiàn)有的圖像采集技術(shù)、圖像處理技術(shù)和圖像識別技術(shù),可以實現(xiàn)液晶屏數(shù)字的識別,常用的方法有神經(jīng)網(wǎng)絡(luò)和模版匹配,識別的時間、識別精度和系統(tǒng)的便攜性是識別系統(tǒng)的關(guān)鍵。
現(xiàn)有的識別系統(tǒng)大都是以計算機(jī)為載體,不能實現(xiàn)隨時隨地識別液晶屏的要求。近年以來,智能手機(jī)系統(tǒng)尤其是安卓系統(tǒng),以其開放性、易開發(fā)和基于Linux操作系統(tǒng)等優(yōu)勢,獲得了大量的用戶。安卓系統(tǒng)提供本地接口(JNI)功能,使開發(fā)者可以通過接口調(diào)用庫文件,不僅可以使用Java語言進(jìn)行開發(fā),而且可以使用輕量級且高效的C/C++語言編寫。安卓的本地接口功能為實現(xiàn)圖像處理提供了方便。通過調(diào)用計算機(jī)視覺庫文件,安卓開發(fā)人員可以方便進(jìn)行圖像的處理和圖像的識別?;诖?,本文提出基于安卓手機(jī)的液晶屏數(shù)字識別系統(tǒng),通過安卓手機(jī)拍照,獲取液晶屏圖像,利用圖像處理技術(shù)對圖像進(jìn)行處理,最后采用三層BP神經(jīng)網(wǎng)絡(luò)對圖像進(jìn)行識別,隨時隨地、快速、準(zhǔn)確地識別液晶屏圖像。
一.識別系統(tǒng)流程
圖像識別技術(shù)是利用計算機(jī)視覺采集物理對象,以圖像數(shù)據(jù)為基礎(chǔ),讓機(jī)器模仿人類視覺,自動完成某些信息的處理功能,達(dá)到人類所具有的對視覺采集圖像進(jìn)行識別的能力,以代替人去完成圖像分類及識別的任務(wù)。圖像模式識別系統(tǒng)通常由五個模塊組成,如圖1所示。

二.圖像預(yù)處理及特征提取
由安卓手機(jī)拍照成功后得到液晶屏圖像,這里選取拍照條件不是很理想的情況下獲取的照片,如下圖2所示。

由上圖2所示,得到的圖像是彩色圖像,由于光照強(qiáng)度等原因,液晶屏圖像中常有許多噪聲點。為了得到精確圖像,本文對圖像進(jìn)行灰度化處理、大津法二值化處理和開運(yùn)算處理。下圖3中(a)、(b)和(c)分別為灰度化處理、大津法二值化處理和開運(yùn)算處理后的結(jié)果。

1.圖像傾斜矯正
在拍攝過程中由于拍攝角度等因素,導(dǎo)致圖像會有一定角度的傾斜,如圖3(c)所示。圖像的傾斜將會增加后續(xù)字符分割和特征提取的難度,甚至導(dǎo)致提取到的特征值是錯誤的,進(jìn)而嚴(yán)重影響字符識別的精度。為了便于圖像后續(xù)處理,需要對圖像進(jìn)行傾斜矯正。
對于液晶屏圖像,考慮采用霍夫變換的方法求其傾斜角。通過霍夫變換,可以取得圖像中所有直線的端點。為了便于快速、高效地求取圖像的傾斜角,先對圖像進(jìn)行膨脹處理和邊緣檢測。
膨脹是指將圖像與核進(jìn)行卷積,核可以是任何形狀或大小。通過圖像的膨脹操作,可以將圖像中的高亮區(qū)域逐漸增加。對于圖3(c),先進(jìn)行反色處理,然后采用7×7的矩形內(nèi)核膨脹處理5次。膨脹處理后的圖像包含有許多直線,對膨脹處理圖像進(jìn)行邊緣檢測。設(shè)定上下限閾值比為3:1,通過Canny邊緣檢測得到的邊緣圖像。圖4中(a)和(b)分別是對圖3(c)進(jìn)行膨脹和邊緣檢測后的結(jié)果。

由圖4(b)可以看出,經(jīng)膨脹處理和邊緣檢測后的圖像可以將液晶屏數(shù)字的輪廓勾勒出來。對圖4(b)進(jìn)行霍夫變換,可以獲取圖像中每條線段的端點,進(jìn)而可以求其反正切函數(shù),即求得每條線段與橫軸之間的夾角。對其余傾斜角求取平均值,即認(rèn)為是圖3(c)的傾斜角度。
根據(jù)傾斜角將圖3(c)進(jìn)行旋轉(zhuǎn)得圖5。

2.字符分割及歸一化
字符的分割技術(shù)可以將單個字符從圖像中分割出來。直方圖廣泛應(yīng)用于計算機(jī)視覺應(yīng)用中,可以對圖像的數(shù)據(jù)進(jìn)行統(tǒng)計,獲得數(shù)據(jù)分布的統(tǒng)計圖。
對于一個大小為X×Y的二值化圖像,定義其在橫軸和縱軸的投影分布函數(shù)為Hx(i)(i=1,2,…,X)和Hy(i)(i=1,2,…,Y),其中,X代表橫軸的坐標(biāo),Y代表縱軸的坐標(biāo),初始化時設(shè)置函數(shù)值均為0。遍歷該圖像中的像素點,如果該像素點為黑色像素點,則將該像素點對應(yīng)的投影分布函數(shù)Hx(i)和Hy(i)分別加1。最后,得出圖像在橫軸和縱軸的投影分布函數(shù)Hx(i)和Hy(i)。利用縱軸和橫軸方向分布函數(shù)中波峰和波谷的位置[9],根據(jù)字符和空白在縱軸和橫軸投影的不同,得出各個字符的頂、底、左端和右端在圖像中位置。
根據(jù)各個字符在圖像中的位置,即可將字符分割,對圖3(c)進(jìn)行字符分割后各個字符如圖6所示。

得到字符在圖像中的位置后,即可將字符從圖像中分割出來。由于實際分割過程中每個字符大小不一致,如圖6所示,所以對分割字符進(jìn)行歸一化處理,使不同字符的大小統(tǒng)一為固定大小,便于后續(xù)字符分割。首先將圖6中字符周圍的空白位置切除,然后采用三次樣條插值的方法,對源圖像附近的4×4個鄰近像素進(jìn)行三次樣條擬合,最后將目標(biāo)像素對應(yīng)的三次樣條值作為目標(biāo)圖像對應(yīng)像素點的值。將字符歸一化以后,所得各個字符如下圖7所示。

3.字符特征提取
將字符從圖像中分割以后,就可以對圖像進(jìn)行特征提取。采用網(wǎng)格法提取字符的21個特征值,用于字符圖像的識別。首先將字符圖像均分為5行3列的區(qū)域,分別求得每個區(qū)域內(nèi)黑色像素所占該區(qū)域的比例,作為字符的15個特征值;然后將字符圖像均分為3行,分別求得每行內(nèi)黑色像素點占該區(qū)域的比例,作為字符圖像的3個特征值;最后,將字符圖像均分為3列,分別求得每列內(nèi)黑色像素點占該區(qū)域的比例,作為字符圖像的另外3個特征值。共提取字符圖像的21個特征值,用于字符圖像的識別。
三.字符識別
用誤差反向后傳算法即BP神經(jīng)網(wǎng)絡(luò)來進(jìn)行數(shù)字字符的識別。BP神經(jīng)網(wǎng)絡(luò)由Rumelhart和McClelland于1985年提出,實現(xiàn)了Minsky和Papert認(rèn)為不能實現(xiàn)的多層網(wǎng)絡(luò)的設(shè)想。
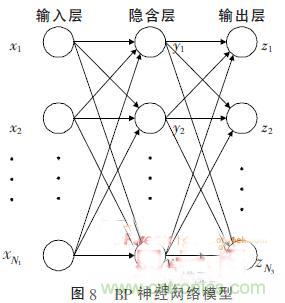
三層BP神經(jīng)網(wǎng)絡(luò)的模型如圖8所示,包括輸入層、隱含層和輸出層,各層間由連接權(quán)值構(gòu)成。BP神經(jīng)網(wǎng)絡(luò)的訓(xùn)練過程由信號的正向傳播和誤差的反向傳播兩個過程組成,其學(xué)習(xí)的本質(zhì)是各連接權(quán)值的動態(tài)調(diào)整。隨著網(wǎng)絡(luò)的不斷學(xué)習(xí),權(quán)值也不斷的調(diào)整,直到誤差減少到可接受的程度或者訓(xùn)練達(dá)到預(yù)定的訓(xùn)練次數(shù)。
1.網(wǎng)絡(luò)結(jié)構(gòu)設(shè)計
2.3節(jié)說明了提取字符的21個特征值,本系統(tǒng)BP神經(jīng)網(wǎng)絡(luò)的輸入層采用21個節(jié)點,分別對應(yīng)字符的21個特征值。數(shù)字字符的識別結(jié)果共10個,本文用各個數(shù)字對應(yīng)的四位二進(jìn)制數(shù)表示其對應(yīng)的期望輸出,即輸出層采用4個節(jié)點。
由理論分析證明,具有單隱層的BP神經(jīng)網(wǎng)絡(luò)即可滿足大部分的設(shè)計需求,本文中采用單隱層。
BP神經(jīng)網(wǎng)絡(luò)隱含層節(jié)點數(shù)的設(shè)計與訓(xùn)練樣本數(shù)的多少、樣本噪聲的大小及樣本中蘊(yùn)含規(guī)律的復(fù)雜程度密切相關(guān)。實際應(yīng)用中常用試湊法確定最佳隱節(jié)點個數(shù)。下面是一些確定隱節(jié)點數(shù)的經(jīng)驗公式:

隱節(jié)點數(shù),n為輸入層節(jié)點數(shù),l為輸出層節(jié)點數(shù),為1~10之間常數(shù)。
經(jīng)過分析與實際檢驗,本系統(tǒng)采用10個隱節(jié)點數(shù)時,可以使網(wǎng)絡(luò)誤差很小,同時具有很高的訓(xùn)練精度,訓(xùn)練速度也很快,所以采用10個隱節(jié)點數(shù)。
網(wǎng)絡(luò)訓(xùn)練所需樣本數(shù)取決于輸入輸出的非線性映射關(guān)系的復(fù)雜程度,映射關(guān)系越復(fù)雜,為保證映射精度,所需要的樣本數(shù)就越多。對于本系統(tǒng)而言,當(dāng)每個數(shù)字字符取10個樣本,總共取100個樣本的時候,就可以訓(xùn)練出比較理想的BP神經(jīng)網(wǎng)絡(luò)。
2.生成訓(xùn)練樣本和測試樣本
本系統(tǒng)收集了1400張液晶屏數(shù)字的圖像,任意選取100張作為訓(xùn)練樣本,剩余1300張作為測試樣本。
3.訓(xùn)練神經(jīng)網(wǎng)絡(luò)
如果用安卓手機(jī)來進(jìn)行BP神經(jīng)網(wǎng)絡(luò)的訓(xùn)練,消耗的時間非常長。為了節(jié)省時間,用計算機(jī)進(jìn)行BP神經(jīng)網(wǎng)絡(luò)的訓(xùn)練。采用VC++平臺,根據(jù)訓(xùn)練樣本訓(xùn)練三層BP神經(jīng)網(wǎng)絡(luò),訓(xùn)練成功后將BP神經(jīng)網(wǎng)絡(luò)模型移植到安卓手機(jī)中。
4.系統(tǒng)測試
圖9為本系統(tǒng)對圖2的識別結(jié)果,可以看到,該系統(tǒng)可以快速實現(xiàn)液晶屏數(shù)字的識別。

用1 300個測試樣本對識別系統(tǒng)進(jìn)行檢測,檢測結(jié)果表明本系統(tǒng)正確識別率高達(dá)97.8%,可以實現(xiàn)液晶屏數(shù)字的精確識別。
四.結(jié)論
現(xiàn)有的液晶屏數(shù)字識別技術(shù)大都是以計算機(jī)作為載體來實現(xiàn)的,不便于實現(xiàn)隨時隨地進(jìn)行液晶屏的識別。針對這個問題,以安卓手機(jī)為載體,通過拍照獲取圖像,調(diào)用計算機(jī)視覺庫實現(xiàn)圖像的預(yù)處理和特征提取,用訓(xùn)練的三層BP神經(jīng)網(wǎng)絡(luò)模型實現(xiàn)液晶屏數(shù)字的識別。檢測結(jié)果表明,該系統(tǒng)可以隨時隨地、快速、高效地實現(xiàn)液晶屏數(shù)字的識別。


