

【導(dǎo)讀】PCIe接口自從被推出以來,已經(jīng)成為了PC和Server上最重要的接口。為了更高了數(shù)據(jù)吞吐率,PCI-SIG組織不斷刷新接口標準,從PCIe 3.0的8GT/s數(shù)據(jù)速率,到PCIe 4.0的16GT/s數(shù)據(jù)速率,再到PCIe 5.0的32GT/x。PCI-SIG組織實現(xiàn)了在速率翻倍的同時,仍能保持使用普通的FR4板材和廉價接插件,主要源自兩個方面的改進,一是使用128b/130b編碼來代替8b/10b編碼,使得編碼效率大幅提高;另一個是使用動態(tài)均衡技術(shù),來代替先前代的靜態(tài)均衡技術(shù)。
這里聚焦于PCIe 3.0和4.0中的動態(tài)均衡技術(shù),介紹其原理、實現(xiàn)及其相關(guān)的一致性測試。這樣一種動態(tài)均衡技術(shù),在spec中被稱作“Link Equalization”(鏈路均衡,簡稱為LEQ)。本系列文章分上下兩篇,本文理論篇主要介紹PCIe 3.0/4.0的鏈路均衡的工作原理,下一篇實踐篇則側(cè)重于鏈路均衡的測試和調(diào)試。
另外,泰克PCI Express專家David Bouse將在4月10日(周五)13:00-16:00直播課堂【PCI Express 5.0規(guī)范更新解讀和測試揭秘】講解如何解決PCIe 5.0的新測試挑戰(zhàn)https://info.tek.com/cn-pcie-mofu.html。
PCIe 3.0 & 4.0的鏈路均衡
在PCIe 3.0和4.0中的鏈路均衡技術(shù)相較于先前代要復(fù)雜得多,這樣一種動態(tài)均衡技術(shù)可以分為兩個方面進行討論。
● 均衡特性方面:從這個方面來說,相對于先前代的均衡來說,3.0和4.0中的均衡技術(shù)的硬件性能指標要求更高了。
● 協(xié)議方面:為了實現(xiàn)動態(tài)地調(diào)整均衡設(shè)置,需要協(xié)議層的配合,這是通過PHY層的LTSSM狀態(tài)機中的Recovery.Equalization子狀態(tài)來實現(xiàn)的。
先來從均衡特性的角度來看看PCIe 3.0和4.0的均衡,如下展示了在PCIe 3.0/4.0中所使用的全部均衡技術(shù),在Tx端有FFE(Feed Forward Equalizer,前饋均衡器);在Rx端有:CTLE(Continuous Time Linear Equalizer,連續(xù)時間線性均衡器)和DFE(Decision Feedback Equalizer,判決反饋均衡器)。通過FFE和CTLE,可以去除大部分由ISI所引入的抖動;通過DFE可以進一步去除ISI,它還能去除部分的阻抗失配所造成的反射。通過這些均衡處理,就能夠最大程度上地保證在接收端判決輸入處將眼圖打開。
除了上述這些均衡特性上的支持外,在協(xié)議層(LTSSM)中還規(guī)定需要通過協(xié)議的方式來動態(tài)調(diào)整鏈路上的均衡設(shè)定值,這整個過程稱作鏈路均衡(Link Equalization,LEQ)。在鏈路均衡過程中:
● 本地端按照某個初始Tx EQ的設(shè)定來發(fā)送數(shù)據(jù);
● 對端在接收到數(shù)據(jù)時,會根據(jù)誤碼率或信號質(zhì)量來判斷該Tx EQ是否合適;
● 若不合適,對端會通過協(xié)議向本地端請求一個新的Tx EQ值;
● 本地端在接收到這個請求值之后,會改變Tx EQ的值。
通過這一動態(tài)過程,就能夠保證鏈路上的Tx EQ為最優(yōu)值。與此同時,本地端和對端也會同時調(diào)整Rx EQ。通過動態(tài)地調(diào)整Tx EQ和Rx EQ,就能夠靈活地適應(yīng)不同的信道情況。
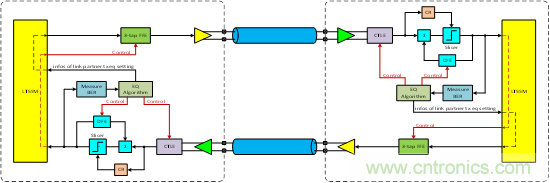
圖1 LEQ硬件實現(xiàn)的模塊框圖
發(fā)送端的均衡:FFE
在PCIe 3.0 & 4.0中使用的都是3-tap FFE,如圖 2a所示。其中,為數(shù)字信號,建模時取值為±1;為FFE的抽頭系數(shù);為發(fā)送端的模擬信號輸出。
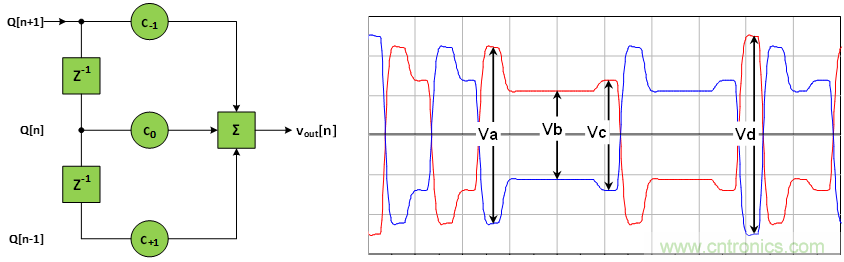
(a)FFE的模型框圖 (b) FFE的模擬電壓輸出
圖2 PCIe 3.0 & 4.0發(fā)送端所使用的3-tap的FFE
理想情況下的差分電壓幅度有:23÷2=4種可能性,這四個電壓幅度在PCIe標準中(如圖 2b所示)分別被標記為Va,Vb,Vc,Vd。
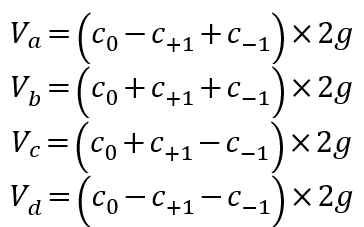
其中,Vb被稱作去加重電壓(de-emphasis voltage),Vc被稱作預(yù)沖電壓(preshoot voltage);Vd被稱作最大幅度電壓(boost voltage),PCIe標準中沒有為Va取一個專門的名字。在此基礎(chǔ)上,標準中通過三組比值來完備地描述FFE的性能:
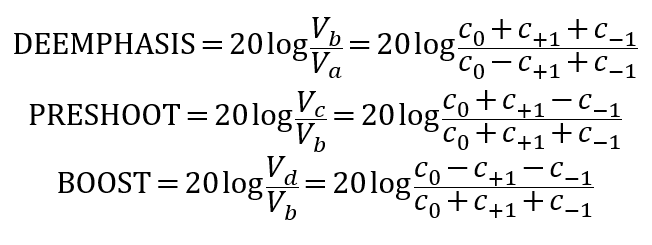
若不加限制的來說,那么形成的組合有無窮多個。但并不是所有的組合在實際應(yīng)用中都是合適的。其中一個最重要的約束條件就是:去加重電壓Vb不能過小,過小的去加重電壓會導(dǎo)致輸出信號在接收端的眼高過低。因此通過BOOST比值對去加重地電壓幅值進行限制:對于滿擺幅的Tx輸出,規(guī)范要求BOOST≤9.5dB;對于減擺幅的Tx輸出,規(guī)范要求BOOST≤3.5dB。最終會形成一個如圖 3類似的矩陣表,圖中系數(shù)的粒度為1/24。在實際應(yīng)用中可以是其他的粒度值,例如1/64;更小的粒度能夠使系數(shù)空間的取值可能性更多,在LEQ調(diào)節(jié)時也更精細。
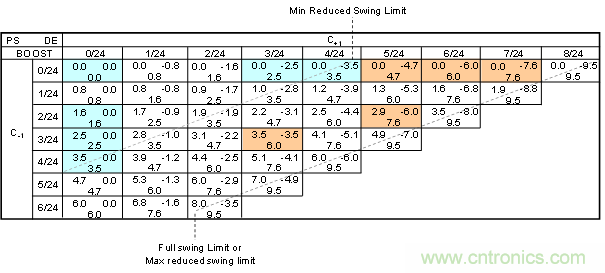
圖3 發(fā)送端均衡的系數(shù)空間的矩陣表舉例
鑒于系數(shù)空間上的取值可能性較多,PCI-SIG協(xié)會在開發(fā)協(xié)議的過程中,廣泛地研究了在不同插入損耗下最優(yōu)的系數(shù)取值組合;最后選定了若干個特定的系數(shù)取值組合,并把它們稱作預(yù)設(shè)定值(preset),在實際的LEQ過程中,鏈路雙方就可以先采用預(yù)設(shè)定值進行粗調(diào);若還認為鏈路的均衡設(shè)置仍然沒有達到最優(yōu),可以進一步通過系數(shù)空間的方式進行細調(diào),最終達到速度和精度的平衡。
接收端的均衡:CTLE和DFE
在PCIe 3.0 & 4.0 基礎(chǔ)規(guī)范中,并沒有明確地規(guī)定接收端的結(jié)構(gòu)是怎樣的;而只是從測量的角度對接收端性能進行了規(guī)定。相反地,在規(guī)范中定義了一個行為級CTLE和行為級DFE。這些行為級模型可以作為設(shè)計指南;并且為了使得待測對象能夠通過規(guī)范的要求,一般來說用戶所設(shè)計的接收端性能至少要等于這些行為級模型的性能,可以強于這些行為級模型,但不能弱于這些行為級模型。
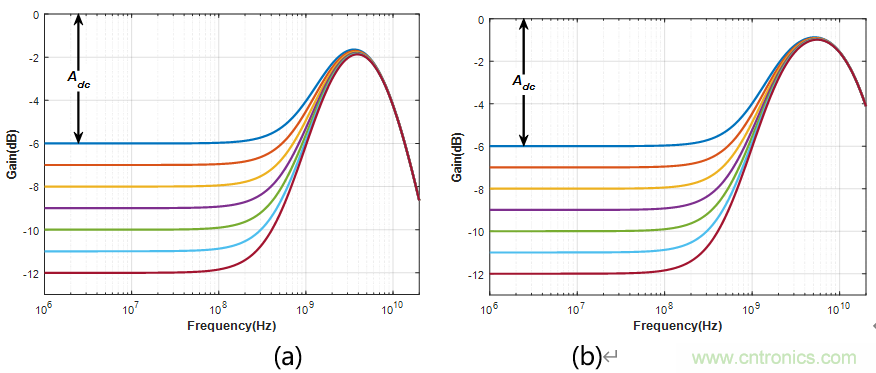
(a) (b)
圖4 行為級CTLE的頻響曲線:(a) PCIe 3.0 (b) PCIe 4.0
發(fā)送端的輸出在經(jīng)過一段很長的FR4走線之后,僅僅使用CTLE,可能是不夠的。因此在PCIe 3.0 & 4.0中,還使用了DFE的技術(shù)。在3.0中,使用1-tap的DFE,而在4.0,由于速率相對于3.0翻倍了;所以使用2-tap的DFE,以便移除更大的ISI。
與線性均衡器FFE和CTLE相比,DFE為一種非線性均衡器。DFE的基本想法是:若已經(jīng)正確接收了之前的比特數(shù)據(jù)的話;那么先前的比特數(shù)據(jù)對當(dāng)前比特所產(chǎn)生的影響就是已知的;從而我們就可以通過反饋的方式進行補償,這樣就能夠進一步消除抖動和噪聲的影響。不難看出這里的非線性體現(xiàn)在:反饋回來的信號是經(jīng)過判決之后的數(shù)字信號;而判決電路是一種非線性電路。顯然,反饋通路上的抽頭數(shù)目越多,那么對抖動和噪聲的消除可能就越好;這也就是為什么3.0中使用1-tap的DFE,而在4.0中使用2-tap的DFE。
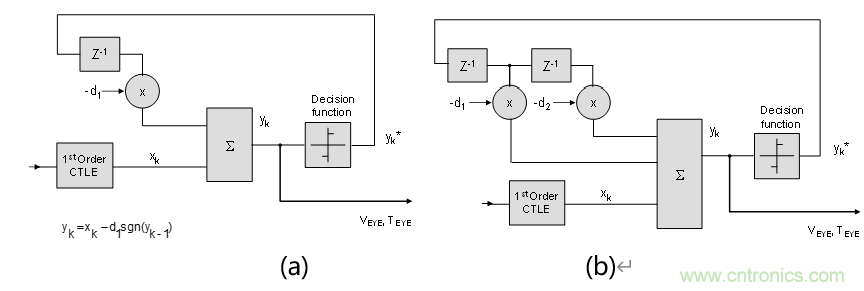
(a) (b)
圖5 行為級DFE的結(jié)構(gòu):(a) PCIe 3.0 (b) PCIe 4.0
鏈路均衡過程
鏈路上的兩端剛開始建立通信的時候,并不知道整個信道的物理特性是怎樣的,例如插入損耗多大,是否有阻抗不連續(xù)等。由于PCIe 3.0和4.0的插入損耗允許的變化范圍很大,一個靜態(tài)的均衡設(shè)置并不能覆蓋所有的情況。這樣就需要鏈路上的雙方根據(jù)當(dāng)前物理信道的特性,來動態(tài)地調(diào)整均衡設(shè)置,使得均衡設(shè)置對于當(dāng)前的物理信道來說是最優(yōu)的。假設(shè)Port A和Port B是一個鏈路上的兩端,那么鏈路均衡過程要做的事情有:
● 配置Port A和Port B的初始均衡設(shè)置;
● 配置從Port A Tx à Port B Rx這一方向的均衡設(shè)置;
● 配置從Port B Tx à Port A Rx這一方向的均衡設(shè)置;
下面我們以Port A Tx à Port B Rx這一方向來說明鏈路均衡時如何實現(xiàn)的。如圖 6所示,在8GTs/或者16GT/s速率下的鏈路開始建立通信時,是以初始的未優(yōu)化的TX EQ在發(fā)送TS1/TS2序列,并且Port A在TS1/TS2序列中表明其所用的TX EQ的值。
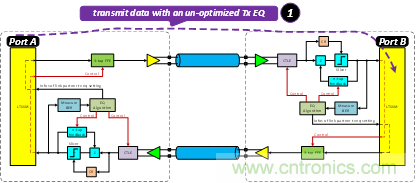
圖6 LEQ: 本地端發(fā)送未經(jīng)優(yōu)化的初始TX EQ
當(dāng)Port B Rx在接收到這些TS1/TS2序列時,芯片內(nèi)部存在一塊電路或者一套算法來評估當(dāng)前的TX EQ是否合適,若認為不合適,就會如圖7所示,發(fā)送TS1序列來請求一個新的TX EQ。
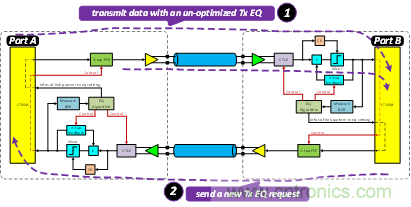
圖7 LEQ:對端請求一個新的TX EQ
隨后,Port A會接收到請求設(shè)置TX EQ的TS1序列,如圖8所示,調(diào)整其TX端的FFE的設(shè)置。
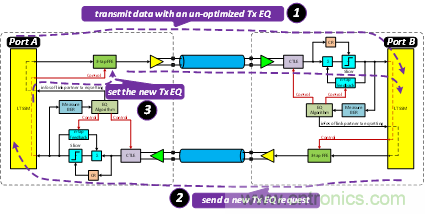
圖8 LEQ:本地正確地接收到了對端的請求,設(shè)置新的TX EQ
Port A在調(diào)整完Tx FFE的設(shè)置之后,如圖9所示,會將新的TX EQ設(shè)置值更新到TS1/TS2的序列之中,發(fā)送到Port B端。若Port B仍然覺得這個時候的TX EQ不是最優(yōu),那么仍然會重復(fù)圖中的2~4步驟,直到達到最優(yōu)的TX EQ。當(dāng)然上述過程并不能無限進行下去,必須要在大概32ms的范圍進行完。
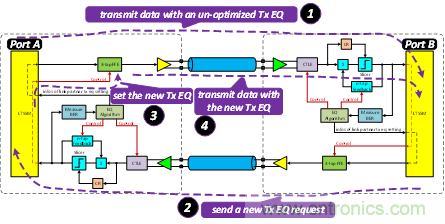
圖9 LEQ:本地端告知對端已成功設(shè)置新的TX EQ
在上述2~4步驟的同時,Port B的RX端也在不停地調(diào)整其RX EQ,如圖 10所示。如圖6~圖10中所討論的,LEQ是基于請求-響應(yīng)機制來完成動態(tài)均衡的。在PCIe的規(guī)范中,LEQ總共包含四個階段:Phase 0、Phase 1、Phase 2、Phase 3。其中上行端口包含全部四個過程;而下行端口不包含Phase 0。
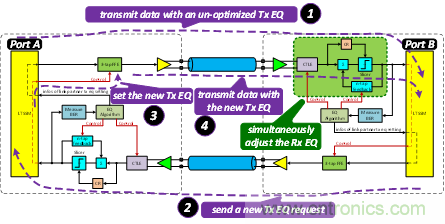
圖10 LEQ:整個過程中同時調(diào)整RX EQ
通過圖11不難看出,在LEQ過程中,上行端口和下行端口的行為是有區(qū)別的。以上描述的是在LEQ過程中鏈路上的雙方如何調(diào)整Tx EQ。而對于Rx EQ,根據(jù)Base規(guī)范中的說明,在整個LEQ的過程、以及在后續(xù)正常工作的過程中,鏈路雙方都可以一直調(diào)整Rx EQ。
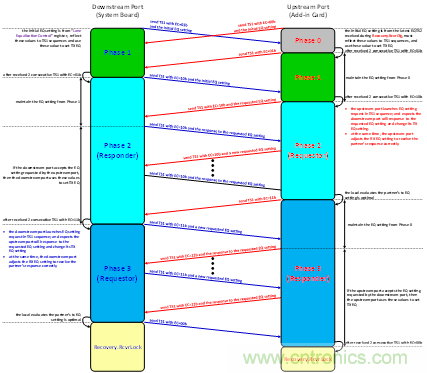
圖11 LEQ的狀態(tài)跳轉(zhuǎn)示意圖
關(guān)于泰克科技
泰克公司總部位于美國俄勒岡州畢佛頓市,致力提供創(chuàng)新、精確、操作簡便的測試、測量和監(jiān)測解決方案,解決各種問題,釋放洞察力,推動創(chuàng)新能力。70多年來,泰克一直走在數(shù)字時代前沿。歡迎加入我們的創(chuàng)新之旅,敬請登錄:tek.com.cn
推薦閱讀:



